近日,腾讯云小微提出的多语言预训练模型“神农MShenNonG”以平均分85分的成绩登顶XTREME榜单。与此同时,该模型仅包含5亿级别的小参数量,也一举刷新业界记录。
据了解,该榜单是目前最受国内外行业公司认可的多语言评测榜单,研究人员以多语言预训练模型在此榜单的表现作为其跨语言迁移能力的评价标准。
目前,全球有超过6900种语言,其中大多数语种都没有足够的数据支撑研究者将其单独训练成成熟模型。腾讯云小微深耕知识挖掘、语义理解技术以及预训练技术,“神农MShenNonG”此次登顶XTREME榜单,代表了其从单语言到多语言理解能力的一个显著扩展,将跨语言迁移开发由市场平均的月级降低至10天。同时,“神农”系列的预训练模型已应用于云小微全系列产品矩阵,可显著提升AI语音助手、智能客服机器人、数智人等产品的多项技术指标,助力出海企业快速落地本地化服务。
刷新行业记录,跨语言迁移开发周期缩短至10天
凭借对自然语言应用程序等领域发展研究的积极作用,XTREME榜单备受业界认可。
由于大多数的NLP预训练模型主要为中文、英文等高资源语种,低资源小语种的研究并未得到足够重视。2020年,来自 CMU、谷歌研究院和 DeepMind 的科学家们提出了覆盖四十种语言、横跨了12个语系的大规模多语言多任务基准 XTREME,其中包含了9项需要不同句法或语义层面进行推理的任务,并可以为语句文本分类、结构预测、语句检索和跨语言问答等自然语言处理任务提供有效支持。
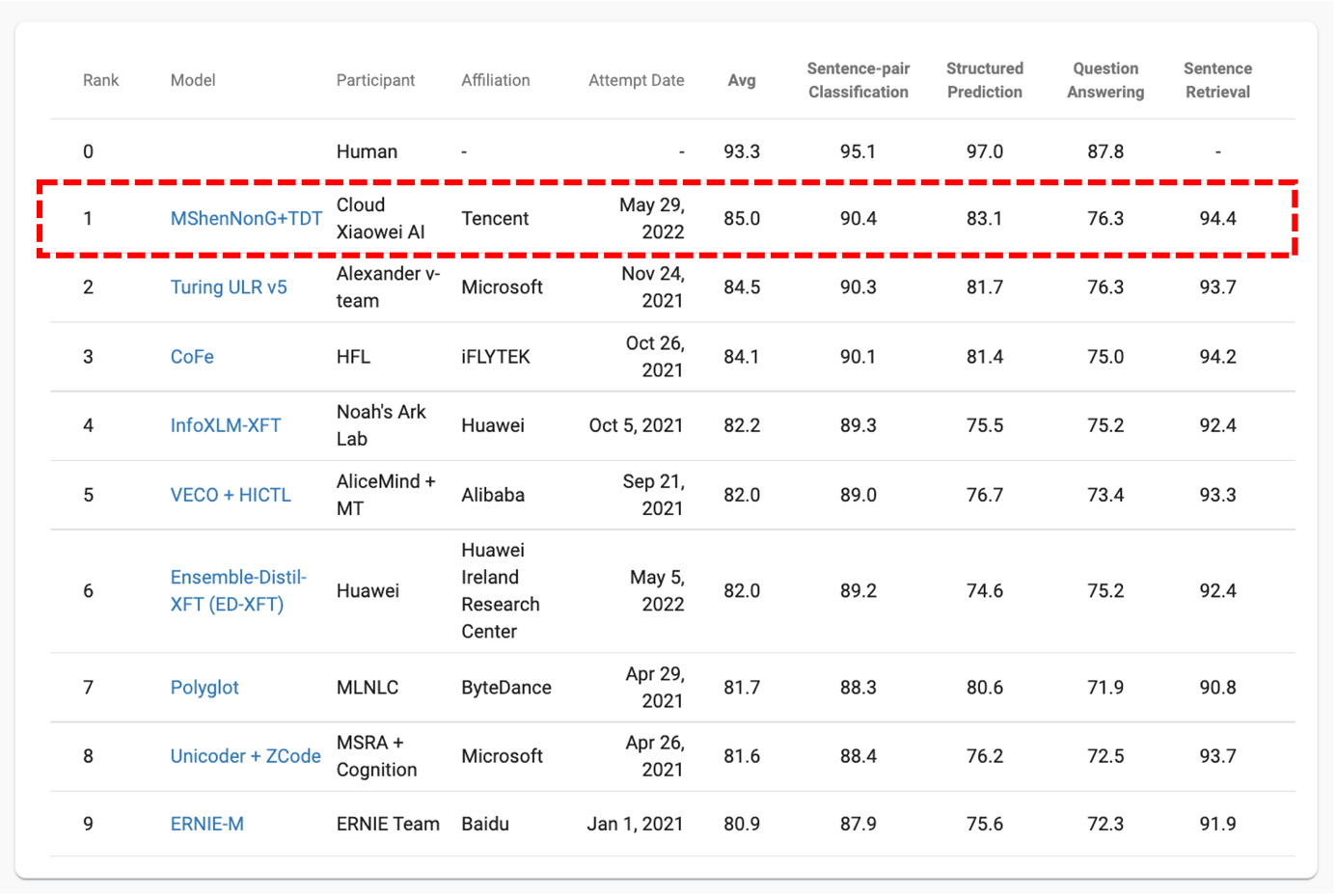
此次登顶XTREME榜单,主要是由于“神农MShenNonG”在以下三个不同维度做了创新性的尝试。
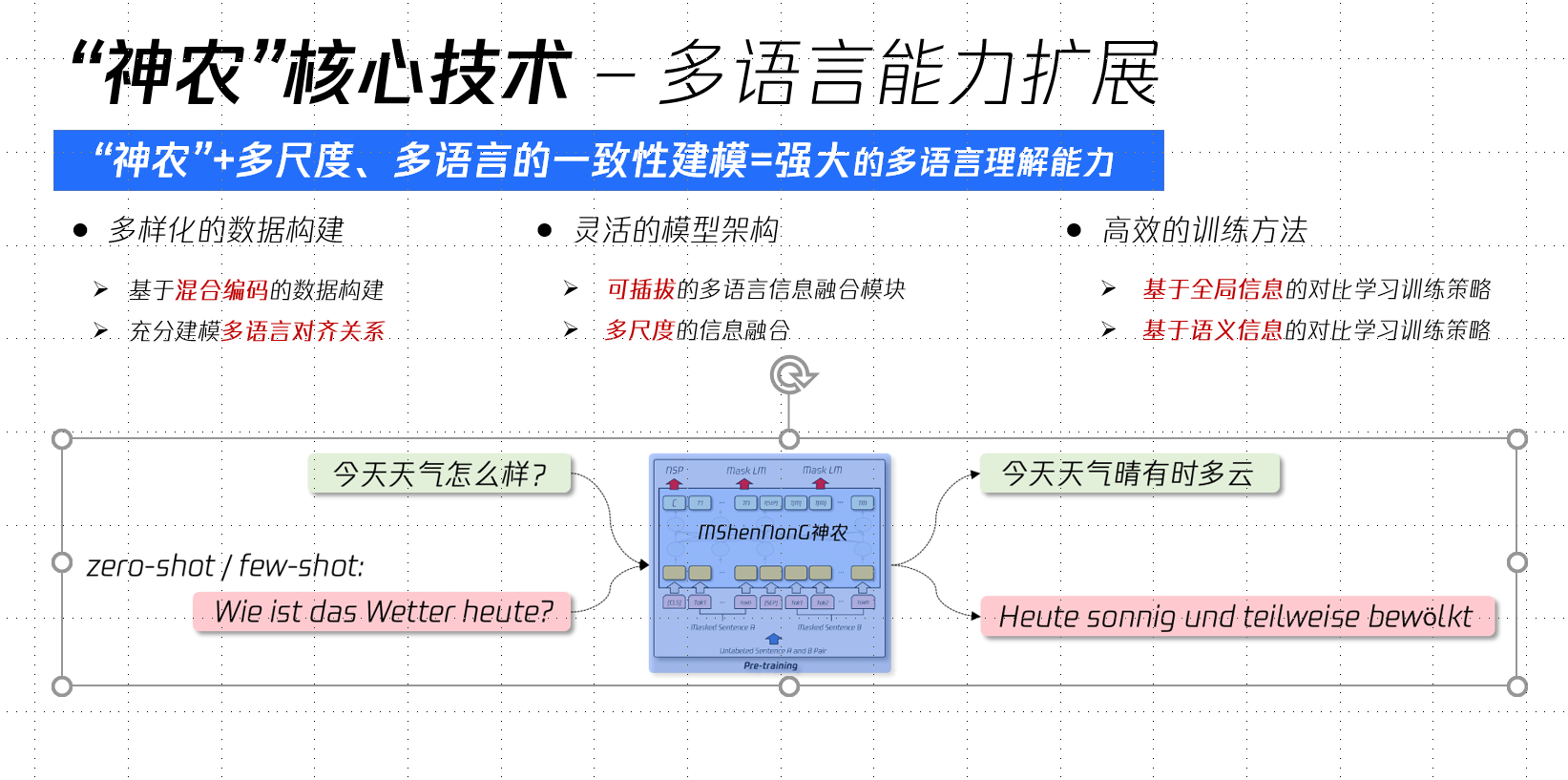
首先,在数据层面,预训练模型的训练数据主要由两种形式的数据构成:单语种句子和双语平行句对。此前的模型处理方法是,对于单语种句子,单纯地将单语种信息输入模型,并以MLM作为训练目标,非常依赖相似语系之间“共享词”的预测来建模各语言间的语义对齐关系;对于平行句对,又依赖平行语料的规模和组合,模型对其对齐关系的建模存在一定缺陷。为缓解以上问题,腾讯云小微研究团队提出了基于混合编码的数据构造方式,分别利用双语对齐词典和句子检索工具,构造大量的“多语言混合”训练数据。
其次,在模型层面,研究团队提出了一种可插拔的、基于多尺度的多语言信息融合模块,分别从词级别和句子级别多个尺度融入多语言信息,期望在训练过程中,加强所有语种的词向量的更新和对齐,解决多语言模型对低资源语种、低频次词汇建模较弱的问题。
第三,在训练方式上,研究团队分别通过语种层面和语义层面引入对比学习策略,使得相同语义的表示相互拉近,不同语义的表示相互远离,进一步强化多语言预训练模型对于多语言的语义建模能力和语义匹配能力。
值得注意的是,研究团队重视多尺度的多语言的一致性建模,以强化预训练模型的跨语言迁移能力,并将跨语言迁移开发由市场平均的月级降低至周级,同时,相较市场平均1个月以上的模型迭代周期,“神农MShenNonG”仅需10天。
多次登顶权威榜单 神农以技术优势探索出海场景
“神农MShenNonG”登顶XTREME榜单,依托于腾讯云小微团队技术研发和行业知识的长期积累。此前,腾讯云小微的中文预训练模型ShenNonG就以十亿级参数量一举登顶CLUE总排行榜、1.1分类任务、阅读理解任务和命名实体任务四个榜单,刷新行业记录。
专注于语义理解技术以及预训练技术的研发,此次登顶XTREME榜单代表了腾讯云小微从单语言到多语言理解相关技术的一个扩展。目前,“神农”系列的预训练模型已应用于全系列产品矩阵,可显著提升AI语音助手、智能客服机器人、数智人等产品的多项技术指标。
随着开发的不断成熟,优势产品向海外拓展成为不少国内企业的选择。但产品出海通常要面临适应新语种、业务本地化的挑战。过往,以机器翻译的方式将单语种迁移到多语言场景,不仅费时费力,效果也差强人意。相对于传统的机器翻译模式,腾讯云小微“神农MShenNonG”预训练模型有着低成本、低门槛的优势,以轻量参数为多行业、小语种提供跨语言迁移服务,助力企业降本增效,落地出海业务。
未来,腾讯云小微团队还将持续深耕知识挖掘和深度学习技术,探索更多技术落地场景,以科技助力各行业的企业更好地服务用户,为社会创造更多价值。






最新评论